BigData / Hadoop basics
Hadoop is a opensource framework that facilitates the distributed processing of large data sets across clusters of computers using simple programming models.
Hadoop provides the reliable, scalable way of distributed computing.
It is designed to scale up from single machine(server) to thousands of machines, each offering its own local computation and storage. The hadoop software library is designed in a way it is capable of detecting and handling failures at the application layer enables delivering a highly-available service on top of a cluster of computers/servers, each of which may be liable to failures.
Hadoop is developed using Java.
Hadoop Common.
The common utilities framework that is leveraged by other Hadoop modules.
Hadoop Distributed File System (HDFS).
A distributed file system that provides high-throughput access to the application data.
Hadoop YARN.
A job scheduling and cluster resource management framework.
Hadoop MapReduce.
A YARN-based system that allows parallel processing of large data sets.
- Business Intelligence.
- Business Analytics.
- Data Warehousing.
- Log Processing.
- Semantic Analysis.
- Video and Image Analysis.
- Searching and Data Mining.
- Pattern recognition.
- Graph Analysis.
- Text Mining.
- Digital signal processing.
Big data refers to the large amount of data, a collection of large datasets that is infeasible to handle/process using existing computer technology/programmming model.
Thus Big Data includes huge volume, high velocity and extensible variety of data, categorized into three types.
Structured data : Relational data, JSON
Semi Structured data : XML.
Unstructured data : Word, PDF, Text and Logs.
- Standalone Mode.
- Pseudo-Distributed Mode.
- Distributed or Clustered Mode.
- Fault Tolerant.
- Complex Data Analytics.
- Scalable and Storage Flexibility.
- cost effective (Commodity Hardware).
- Open Source.
- Fast and flexible.
HDFS (Hadoop Distributed File System) is the file system used by Hadoop Framework for data Storage on Distributed Computing Environment.
HDFS Is exceptionally scalable and faults tolerant.
The features of Hadoop Distributed File Systems are,
- Portable.
- Scalable.
- Reliable.
- Fault tolerant.
- Recovery from Hardware failures.
- Data Coherency.
- Enabling MapReduce Process.
Below are some of the major components of Hadoop Distributed File System (HDFS).
- NameNode.
- DataNode.
- Secondary NameNode.
- Backup Node.
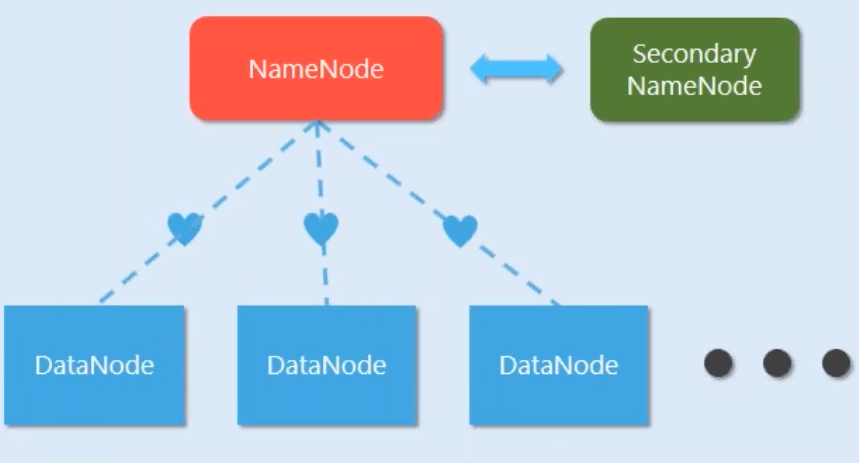
NameNode is a daemon process in HDFS which is responsible for all processes related to storage in Hadoop. It Manages the Hadoop File system namespace. NameNode Itself doesnot store the actual data, whereas it stores the meta data in RAM for supporting faster operations. NameNode is a Single point of failure in Hadoop System.
Meta data files managed by NameNode are,
- FSImage File.
- EditLog File.
DataNode is a commodity hardware which actually stores the data and performs file-level operations as suggested by the NameNode. DataNode sends the signals to NameNode for its status. If DataNode is not able to send heartbeats to the NameNode than Name node marked particular DataNode as dead.
- Slave daemons.
- Serves read/write request from the client.
- Stores actual data.
As name described Secondary NameNode is not a backup of the NameNode. Whereas from time to time it stores the NameNode Metadata files and in the case of NameNode failure It helps NameNode by providing Metadata file. So basically, it only support and provide required file to NameNode in the case of failure.
Backup Node is corresponding to Checkpoint NameNode, but it keeps the updated copy of FsImage in RAM memory and is always synchronized with NameNode.
The below are the identified characteristics of any big data.
- Volume,
- Variety,
- Velocity,
- Value,
- and Veracity.
Volume refers to the scale of data, the main characteristic that makes data big or huge. The amount of data/information over internet from social networks for e.g. are growing exponentially.
Variety refers to the different forms of big data. There are many datatypes in terms of structured data whereas there are no rule/convention for unstructured data.
Velocity refers to the frequency of data to be processed. A streaming online services that work with weather data, GPS data are example of an application that handles the velocity of data.
Value refers to the worthyness of information extracted from the data.
Veracity denotes the uncertainty i.e. trustworthiness of data.
First the files are divided into blocks and then those Blocks are stored on different DataNodes. NameNode stores the metadata. (file information, location etc.)
There are 2 terms used in HDFS Data Storage.
- Block.
- Replication.
Blocks are the smallest unit of storage in HDFS and ranges from 64MB to 128MB. Replication is the copying factor that supports high tolerance features of Hadoop. Default Replication factor is 3, i.e. block would be redundant 3 times on different DataNodes.
- Capture Big Data.
- Process and Analyse.
- Distribute Results.
- Feedback (Audit).
The below are the most commonly input formats used in Hadoop system.
- TextInputFormat.
- KeyValueInputFormat.
- DBInputFormat.
- and SequenceFileInputFormat.
TextInputFormat is the default input format.
The other input formats include,
- CombineFileInputFormat.
- CustomInputFormat.
Functional programming is a way of implementing parallel programming in which one function gets exclusive access to the data that it processes and release the lock on the data when it passes to the other function.
Distributed Programming is the core feature of the Big Data system that supports the Parallel Programming Paradigm and leverages the power of Distributed Storage System.
Below are some of the Distributed Programming available on Hadoop System.
- Hadoop MapReduce.
- Apache Hive.
- Apache Pig.
- Apache Spark.
The available output format in Hadoop system are,
- TextOutputFormat.
- MapFileOutputFormat.
- SequenceFileOutputFormat.
- SequenceFileAsBinaryOutputFormat.
- MultipleOutputFormat.
- MultipalTextOutputFormat.
- MultipalSequenceFileOutputFormat.
TextOutputFormat is the default output format provided by the Hadoop system.
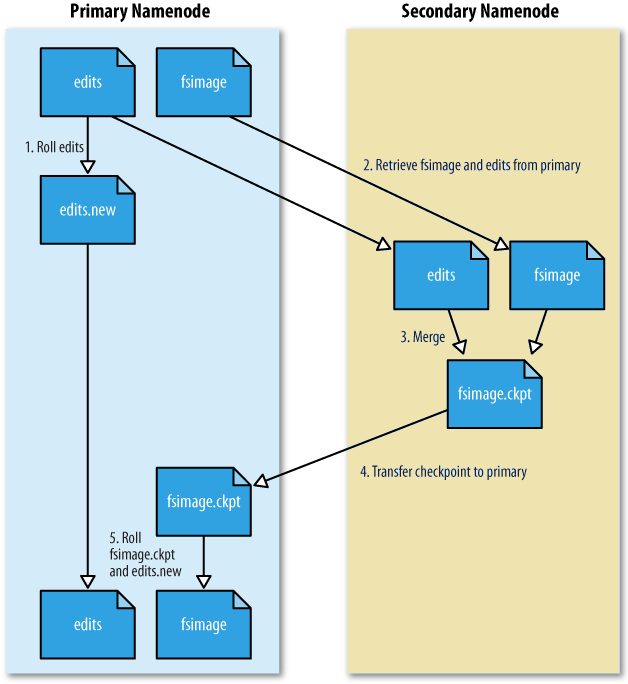
fsImage file contains all the information about modifications/changes made across the cluster ever since the nameNode was started. It is stored in HardDisk memory.
editLog also has metadata about modifications however it has only recent changes (usually past 1 hour). It is maitained in RAM.
Checkpointing refers to the process of combining edit log with FSImage. Secondary Namenode gets the copy of fsImage and editLog from NameNode and it consolidates the files to prepare the final FSImage file.
FsImage (final) = fsImage + editLog
fs.checkpoint.period controls the number of seconds between two periodic checkpoints. Default value is 3600 Sec (1 hour).
fs.checkpoint.size refers to the size of the current edit log (in bytes) that triggers a periodic checkpoint even if the fs.checkpoint.period hasn't expired. The default value is 67108864 bytes.
The block size is the smallest unit of data that a file system can store. The default Block Size on Hadoop 1 is 64MB, Hadoop 2 is 128MB.
Changing the block size in hdfs-site.XML configuration file won't affect the existing data that are already stored in HDFS.
The single point of failure in a Hadoop cluster is the NameNode. While the loss of any other machine does not result in data loss, NameNode loss results in cluster unavailability. The permanent loss of NameNode data would render the cluster's HDFS inoperable.
Therefore, the step should be taken in this configuration to back up the NameNode metadata.
Replication factor facilitates fault tolerance in Hadoop cluster.
HDFS stores files as data blocks and distributes these blocks across the entire cluster. As HDFS was designed to be fault-tolerant and to run on commodity hardware, blocks are replicated a number of times to ensure high data availability. The replication factor is a property that can be set in the HDFS configuration file that will allow you to adjust the global replication factor for the entire cluster.
For each block stored in HDFS, there will be n 1 duplicated blocks distributed across the cluster. For example, the default replication factor is 3, so there would be 1 original block and 2 replicas.While tweaking the block size, a very small block size will increase seek time to read the file that affects performance and making large block size we will lose the parallelism while reading a file.
The HDFS client sends a WRITE request on DistributedFileSystem API.
DistributedFileSystem issue a RPC call to the name node to create a new file in FS namespace. After various checks, client gets the permission or an IOException.
The DistributedFileSystem return FSDataOutputStream to the client for writing data. As the client writes data, DFSOutputStream splits it into packets, which it writes to an internal queue, called the data queue. The data queue is consumed by the DataStreamer, that the name node to allocate new blocks by picking a list of suitable data nodes to store the replicas.
The list of data nodes forms a pipeline based on the replication Level. The default is 3. The DataStreamer streams the packets to the first data node in the pipeline, which stores the packet and forwards it to the second data node in the pipeline. so is the second node does and send it to the third data node.
DFSOutputStream also maintains an internal queue of packets that are waiting to be acknowledged by data nodes, called the "ack queue". A packet gets removed as soon as it has been acknowledged by the data nodes in the pipeline. Datanode sends the acknowledgment once required replicas are created.
The client calls close() on the stream when done which flushes all the remaining packets to the data node pipeline and waits for acknowledgments before contacting the name node to signal that the file is complete. The name node already knows the blocks the file is made up of, so it only has to wait for blocks to be minimally replicated before returning successfully.
Client opens the file it wishes to read by calling open() on the Distributed FileSystem (HDFS).
DistributedFileSystem makes an RPC call to the name node to determine the locations of the blocks for the first few blocks in the file.
For each block, the name node returns the addresses of the data nodes that have a copy of that block and data nodes are sorted according to their proximity to the client.
DistributedFileSystem returns an FSDataInputStream to the client for it to read data from. FSDataInputStream in turns wraps the DFSInputStream which manages the data node and name node I/O.
Client calls read() on the stream. DFSInputStream which has stored the data node addresses then connects to the closest data node for the first block in the file.
Data is streamed from the data node back to the client, which calls read() repeatedly on the stream. When the end of the block is reached.
DFSInputStream will close the connection to the data node and then finds the best data node for the next block.
This library provide filesystem and OS level abstractions and includes the necessary Java files and scripts required to start Hadoop.
This module is required by other Hadoop modules.