DataStructures / Data structures Interview questions
Data structures refers to the way data is organized and manipulated. It helps to find ways to make data access more efficient. When dealing with data structure, we not only focus on one piece of data, but rather different set of data and how they can relate to one another in an organized manner.
A linear data structure traverses the data elements sequentially, in which only one data element can directly be reached. For example Arrays, Linked Lists are linear data structure.
The data items are not arranged in a sequential structure. Every data item is attached to several other data items in a way that is specific for reflecting relationships. Graph and Tree are examples of non linear data structure.
Commonly used data structures are,
- list,
- arrays,
- stack,
- queues,
- graph,
- tree.
The following operations are commonly performed on any data-structure,
Insertion: adding a data item.
Deletion: removing a data item.
Traversal: accessing and/or printing all data items.
Searching: finding a particular data item.
Sorting: arranging data items in a pre-defined sequence.
Array is a data structure used to store homogeneous elements at contiguous locations. Size of an array must be provided before storing data.
A linked list is a linear data structure similar to arrays where each element is a separate object. Each element or node of a list comprises of two items: data and a reference to the next node.
There are 3 types of linked list.
Singly Linked List: Every node stores address or reference of next node in list and the last node has next address or reference as NULL.
Doubly Linked List: There are two references associated with each node, one of the references points to the next node and other to the previous node. Advantage of this data structure is that we can traverse in both the directions and for deletion we don't need to have explicit access to previous node.
Circular Linked List: Circular linked list is a linked list where all nodes are connected to form a circle. There is no NULL at the end. A circular linked list can be a singly circular linked list or doubly circular linked list. Advantage of this data structure is that any node can be made as starting node. This is useful in implementation of circular queue in linked list.
To find the middle element of linked list in one pass, you may maintain two-pointer, one increment at each node while other increment after two nodes at a time so that when first pointer reaches end, second pointer will point to middle element of linked list.
A stack or LIFO (last in, first out) is an abstract data type that serves as a collection of elements, with two principal operations: push, which adds an element to the collection, and pop, which removes the last element that was added. In stack both the operations of push and pop takes place at the same end that is top of the stack. It can be implemented by using both array and linked list.
A queue or FIFO (first in, first out) is an abstract data type that serves as a collection of elements, with two principal operations: enqueue , the process of adding an element to the collection.(The element is added from the rear side) and dequeue , the process of removing the first element that was added. (The element is removed from the front side). It can be implemented by using both array and linked list.
Stack implements LIFO method, addition and retrieval of a data item takes only Ο(1) time. Stack is used where we need to access data in the reverse order or its arrival order. Stacks are used commonly in recursive function calls, expression parsing, depth first traversal of graphs etc.
Two. One queue is used for actual storing of data and another for storing priorities.
- The manipulation of Arithmetic expression,
- Symbol Table construction,
- and Syntax analysis.
A priority queue is a collection of elements such that each element has been assigned a priority.
Stack is LIFO (Last In First Out) data structure while Queue is a FIFO (First In First Out) data structure.
The main difference between singly linked list and doubly linked list is the ability to traverse. In a single linked list, node only points towards next node, and there is no pointer to previous node, which means you can not traverse back on a singly linked list. On the other hand doubly linked list maintains two pointers, towards next and previous node, which allows you to navigate in both direction in any linked list.
Binary Search Tree has some special properties such as left nodes contains items whose value is less than root, right sub tree contains keys with higher node value than root, and there will not be any duplicates in the tree.
Binary Search Tree is also known as ordered or sorted binary trees.
- Compiler Design,
- Operating System,
- Database Management System,
- Statistical analysis package,
- Numerical Analysis,
- Graphics,
- Artificial Intelligence,
- and Simulation.
A data structure that is partially composed of smaller or simpler instances of the same data structure. For instance, a tree is composed of smaller trees (subtrees) and leaf nodes, and a list may have other lists as elements.
Many mathematical functions can be defined recursively such as,
- Factorial,
- Fibonacci,
- Euclid's GCD (greatest common denominator),
- Fourier Transform.
Sorting is not possible in Deletion. Using insertion we can perform insertion sort, using selection we can perform selection sort, using exchange we can perform the bubble sort. But no sorting method can be done just using deletion.
- Sparse matrix,
- Index generation.
B+ tree. in B+ tree, all the data is stored only in leaf nodes, that makes searching easier. This corresponds to the records that shall be stored in leaf nodes.
In a binary tree a node can have maximum two children, or in other words we can say a node can have 0,1, or 2 children.
Its properties are as follows.
The maximum number of nodes on any level i is 2i where i>=0.
The maximum number of nodes possible in a binary tree of height h is 2h-1.
The minimum number of nodes possible in a binary tree of height h is equal to h.
If a binary tree contains n nodes then its maximum possible height is n and minimum height possible is log2 (n+1).
If n is the total no of nodes and e is the total no of edges then e=n-1.The tree must be non-empty binary tree.
If n0 is the number of nodes with no child and n2 is the number of nodes with 2 children, then n0=n2+1.
Multidimensional arrays make use of multiple indexes to store data. It is useful when storing data that cannot be represented using a single dimensional indexing, such as data representation in a chess board game, tables with data stored in more than one column for example geo spatial data.
Based on storage, a linked list is considered non-linear. However on the basis of access strategies a linked list is considered linear.
Dynamic data structure expands and shrinks in size as program runs. It provides a flexible means of manipulating data as it can adjust capacity according to the size of the data.
Data that is stored in a stack follows a LIFO pattern. This means that data access follows a sequence wherein the last data to be stored will the first one to be extracted. Arrays, on the other hand, does not follow a particular order and instead can be accessed by referring to the indexed element within the array.
A dequeue is a double-ended queue in which elements can be inserted or removed from either end.
A graph is a data structure that contains a set of ordered pairs. These ordered pairs are also referred as edges or arcs, and are used to connect nodes where data can be stored and retrieved.
An AVL tree is a type of binary search tree that is always in a state of partially balanced. The balance is measured as a difference between the heights of the subtrees from the root. This self-balancing tree was known to be the first data structure to be designed as such.
AVL Tree is Named after its inventor Adelson, Velski & Landis, are height balancing binary search tree.
push: adds an item to stack.
pop: removes the top stack item.
peek: retrieves the value of top item without removing it.
Linear search for an item in a sequentially arranged data type. These sequentially arranged data items known as array or list, are accessible in a incremental memory location.
Linear search compares expected data item with each of data items in list or array. The average case time complexity of linear search is Ο(n) and worst case complexity is Ο(n2). Data in target arrays/lists need not have to be sorted.
A binary search works only on sorted lists or arrays. This search starts at the middle element which splits the entire list into two parts. This search first compares the target value to the mid of the list. If it is not found, then it takes decision on whether to search on first part or second part if the search value is lesser than middle element or greater vice versa.
Binary search is also known as half-interval search or logarithmic search.
Heterogeneous Linked List is a linked list data-structure that contains or is capable of storing data for different datatypes.
RDBMS implements Array data structure.
Network data model uses Graph.
Hierarchal data model uses Trees.
An expression in which each operator follows its operand is known as postfix expression. The main benefit of this expression is that there is no need to group sub-expressions in parentheses or to consider operator precedence.
A spanning tree is a tree associated with a network. All the nodes of the graph appear on the tree once. A minimum spanning tree is a spanning tree organized so that the total edge weight between nodes is minimized.
A singly list node consists of two fields:data field to store the element and link field to store the address of the next node.
A rooted binary tree has a root node and every node has at most two children.
A full binary tree (proper or plane binary tree) is a tree in which every node in the tree has either 0 or 2 children.
A Complete Binary Tree has all levels completely filled except possibly the last level and the last level has all keys as left as possible.
In Perfect Binary Tree all internal nodes have two children and all leaves are at same level.
A binary tree is balanced if height of the tree is O(Log n) where n is number of nodes.
A degenerate (or pathological) tree is a tree where every internal node has one child. Such trees are performance-wise same as linked list.
Tree traversal is the process to visit all the nodes of a tree. All the nodes are connected via edges (links), we always start from the root (head) node. There are three ways which we use to traverse a tree.
- In-order Traversal,
- Pre-order Traversal,
- Post-order Traversal,
In a weighted graph, a minimum spanning tree is a spanning tree that has minimum weight that all other spanning trees of the same graph.
Hashing is a technique that converts a range of key values into a range of indexes of an array. By using hash tables, we can create an associative data storage where data index can be identified by providing its key values.
Algorithm is a step by step procedure, which defines a set of instructions to be executed in certain order to get the desired output.
Time complexity of an algorithm indicates the total time required by the program to run to completion. It is usually expressed by using the big O notation.
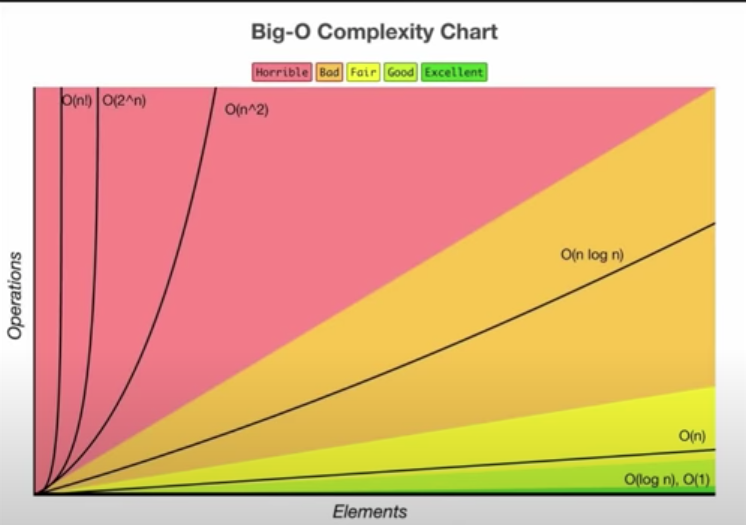
Asymptotic analysis of an algorithm refers to defining the mathematical boundation/framing of its run-time performance. Using asymptotic analysis, we can identify the best case, average case, and worst case scenario of an algorithm.
Asymptotic analysis is input bound so that if there's no input to the algorithm, it is considered to work in a constant time. Other than the "input" all other factors are considered constant.
An algorithm are generally analyzed on 2 factors, time and space. How much execution time and how much extra space required by the algorithm forms basis for analysis.
Quick sort algorithm uses divide and conquer approach. It divides the list into smaller 'partitions' using 'pivot'. The values which are smaller than the pivot are arranged in the left partition and greater values are arranged in the right partition. Each partition is recursively sorted using quick sort.
Bubble sort is a comparison based algorithm in which each pair of adjacent elements is compared and elements are swapped if they are not in order. Bubble sort has the time complexity of Ο(n2), it is the least used sorting strategy for large volume data.
Insertion sort divides the list into two sub-list, sorted and unsorted. It takes one element at time and finds it appropriate location in sorted sub-list and insert it to the sorted sub-list. It iteratively works on all the elements of unsorted sub-list and inserts them to sorted sub-list in order.
Insertion sort builds the final sorted list one item at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort.
List is divided into two parts, the sorted part at the left end and the unsorted part at the right end. It selects the smallest element from unsorted sub-list and places it into the sorted list. This iterates unless all the elements from unsorted sub-list are consumed into sorted sub-list.
This algorithm is not suitable for large data sets as its average and worst case complexities are of Ο(n2), where n is the number of items.
Merge sort algorithm is based on divide and conquer programming approach. This algorithm divides the unsorted list into n sublists, each containing 1 element and repeatedly merge sublists to produce new sorted sublists until there is only 1 sublist remaining.
Shell sort is an unstable quadratic sorting algorithm and it is a generalization of insertion sort.
This algorithm starts by sorting pairs of elements far apart from each other, then progressively reducing the gap between elements to be compared.
Quick sort uses divide and conquer approach and this algorithm divides the list in smaller 'partitions' using 'pivot'. The values which are smaller than the pivot are arranged in the left partition and greater values are arranged in the right partition. Each partition is recursively sorted using quick sort.
A recursive function is a function that makes a call to itself. To prevent infinite recursion a conditional statement is placed that prevent the further calls. For example Fibonacci series can be determined using recursive function.
Huffmans algorithm is associated in creating extended binary trees that has minimum weighted path lengths from the given weights. It makes use of a table that contains frequency of occurrence for each data element.
Backtracking.
| Tree. | Graph. |
| Tree is a special form of graph also called as minimally connected graph having only one path between any two vertices. | A graph vertices can have more than one path, that is, a graph can have uni-directional or bi-directional paths (edges) between nodes. |
| A tree has no loops, no circuits and no self-loops. | Graph can have loops, circuits and also self-loops. |
| There is only one root node and every child have only one parent. | In graph there is no such concept of root node. |
| In trees, there is parent child relationship between nodes. | In Graph there is no such parent child relationship. |
| Trees are less complex in nature then graphs. | Graphs are more complex than trees as it can have cycles, loops. |
| Types of trees are: Binary Tree , Binary Search Tree, AVL tree, Heaps. | Two types of Graphs are Directed and Undirected graph. |
| Tree always has n-1 edges. | In Graph, number of edges depends on the graph. |
| Tree is a hierarchical model. | Graph is a network model. |
| Tree is traversed in Pre-Order, In-Order and Post-Order. | Graph is traversed by DFS: Depth First Search and in BFS : Breadth First Search algorithm. |
A heap is a specialized tree-based data structure that satisfies the heap property that If 'A' is a parent node of 'B', then the key (that is, value) of node A is ordered with respect to the key of node B with the same ordering strategy applyed across the heap.
Heap data structure is always a Binary Tree.
A heap can be of two types, max heap and min heap.
The max heap is a type heap data structure where the value of the root node is greater than or equal to either of its child nodes.

A min-heap is a type of heap data structure where the value of the root node is less than or equal to either of its child nodes.

A Binary tree is a type of tree data structure where each parent node can have at most two child nodes ( 0 to 2 nodes).
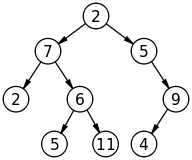
Binary search tree is a binary tree where the left child contains only nodes with values less than the parent node, and where the right child only contains nodes with values greater than or equal to the parent node.
A complete graph is a graph with N vertices and an edge between every two vertices. Given that N is positive integer, there are no loops and every two vertices share exactly one edge.
The symbol KN denotes a complete graph with N vertices.
In graph theory and computer science, an adjacency matrix is a square matrix used to represent a finite graph. The elements of the matrix indicate whether pairs of vertices are adjacent or not in the graph.
An undirected graph is graph with a set of vertex or nodes that are connected together, where all the edges are bidirectional. An undirected graph is sometimes called an undirected network.
In contrast, a graph where the edges point in a direction is called a directed graph.A digraph pr directed graph is a Data Structure containing a vertex set V and an edge/arc set A, where each edge is an ordered pair of vertices. The arcs may be thought of as arrows, each one starting at one vertex and pointing at precisely one other.
In graph theory and computer science, an adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a vertex in the graph.
Incidence matrix is a two-dimensional Boolean matrix, in which the rows represent the vertices and columns represent the edges. The entries indicate whether the vertex at a row is incident to the edge at a column.
Incidence matrix is one of the ways to represent a graph.
A dense graph is a graph in which the number of edges is close to the maximal number of edges.
Sparse graph is a graph in which the number of edges is close to the minimal number of edges.
Adjacency lists are generally preferred because they efficiently represent sparse graphs. An adjacency matrix is preferred if the graph is dense, that is the number of edges is close to the number of vertices squared.
A graph which do contain loops are Non-Simple.
The knapsack problem or rucksack problem is a problem in combinatorial optimization: Given a set of items, each with a weight and a value, determine the number of each item to include in a collection so that the total weight is less than or equal to a given limit and the total value is as large as possible.
Dynamic programming also known as dynamic optimization is a method for solving a complex problem by breaking it down into a collection of simpler subproblems, solving each of those subproblems just once, and storing their solutions using a memory-based data structure.
The next time the same subproblem occurs, instead of recomputing its solution, one simply looks up the previously computed solution, thereby saving computation time at the expense of a modest expenditure in storage space. Each of the subproblem solutions is indexed in some way, typically based on the values of its input parameters, so as to facilitate its lookup. The technique of storing solutions to subproblems instead of recomputing them is called memoization.
Memoization is a term describing an optimization technique where you cache previously computed results, and return the cached result when the same computation is needed again.
Dynamic programming is a technique for solving problems recursively and is applicable when the computations of the subproblems overlap.
Dynamic programming is typically implemented using tabulation, but can also be implemented using memoization.
In bubble sort at i-th iteration you have n-i-1 inner iterations ((n^2)/2), but in insertion sort you have maximum i iterations on i-th step, but i/2 on average, as you can stop inner loop earlier, after you found correct position for the current element. So you have (sum from 0 to n) / 2 which is (n^2) / 4.
Trie is an ordered tree data structure that is used to store a dynamic set or associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the key with which it is associated.
An trie is also called digital tree, radix tree or prefix tree.
Edge cases are inputs that the specification for your function allows but that might be tricky to handle.
An edge case is a problem or situation that occurs only at an extreme (maximum or minimum) operating parameter. For example, a stereo speaker might noticeably distort audio when played at its maximum rated volume, even in the absence of other extreme settings or conditions.
Use Theta to represent complexity when best/average/worst case are equal.
Deletion always occurs at the root of the heap. The root element is removed and it is replaced by the last element in the heap. This satisfies the shape property, however, it violates the order property as the last element would be the smallest(in case of the max heap). The Reheapify operation needs to be performed to satisfy the order property.
Depth is the node is equal to the number of edges to the node from root node. The depth of root node is 0.
Also maximum number of children at level i is 2 to the power of I.
The height of the node is equal to the number of edges in the longest path to the leaf from the node. The depth of a leaf node is 0.
Height of the tree is nothing but the height of the root node.
In a strict binary tree, each node can have either 0 or 2 children.
In complete binary tree, all level except the last are completely filled and all the node are on left as possible and no vacant space on left side.
In perfect binary tree, all levels are completely filled.
Both insertion sort and selection sort have nested loops, one outer and inner loop.
In selection sort, the inner loop is over the unsorted elements. Each pass selects one element and moves it to its final location which is at the current end of the sorted region. In insertion sort, each pass of the inner loop iterates over the sorted elements. Sorted elements are displaced until the loop finds the correct place to insert the next unsorted element.
Merge sort takes O (n log n) in terms of worst case scenario.
Inverted binary tree is the mirror image of the tree where the left of the nodes move to right and vice versa.
A jagged array is an array whose elements are arrays. The elements of a jagged array can be of different dimensions and sizes. A jagged array is also called as array of arrays.
Any application where you want to traverse both sides from a specific point may leverage doubly-linked lists.
- Doubly linked list is used in constructing MRU/LRU (Most/Least Recently Used) cache.
- The browser cache that allows you to hit the BACK-FORWARD pages.
- Undo-Redo functionality.
- A music player which has next and prev buttons.
Binary Heap is a Binary tree that is complete. Except for the last level all its levels are strictly completely filled. A Binary Heap is either a Min Heap or a Max Heap and is suitable to be stored in an array. Binary Heap has many applications like implementations of the priority queue, Heap Sort, etc.
Binary Heap also satisfied the heap ordering property. The order can be 2 types.
Min Heap Property: The value of each node is greater than or equal to the values of its parent, with the minimum-value at the root.
Max Heap Property: The value of each node is lesser than or equal to the values of its parent, with the maximum-value at the root.
An undirected graph is a graph in which edges have no orientation. The edge(u,v) is identical to the edge (v, u).
| BFS (Breadth First Search) | DFS (Depth First Search) |
| BFS(Breadth First Search) uses Queue data structure for finding the shortest path. | DFS(Depth First Search) uses Stack data structure. |
| BFS considers all neighbors first and therefore not suitable for decision making trees used in games or puzzles. | DFS is more suitable for game or puzzle problems. We make a decision, then explore all paths through this decision. And if this decision leads to win situation, we stop. |
| Here, siblings are visited before the children. BFS can be used to find single source shortest path in an unweighted graph, because in BFS, we reach a vertex with minimum number of edges from a source vertex. | Here, children are visited before the siblings. In DFS, we might traverse through more edges to reach a destination vertex from a source. |
| The Time complexity of BFS is O(V + E) when Adjacency List is used and O(V^2) when Adjacency Matrix is used, where V stands for vertices and E stands for edges. | The Time complexity of DFS is also O(V + E) when Adjacency List is used and O(V^2) when Adjacency Matrix is used. |
