BigData / Data pipeline interview questions
A data pipeline is a series of data processing steps. If the data is not currently loaded into the data platform, then it is ingested at the beginning of the pipeline. Then there are a series of steps in which each step delivers an output that is the input to the next step. This continues until the pipeline is complete. In some cases, independent steps may be run in parallel.
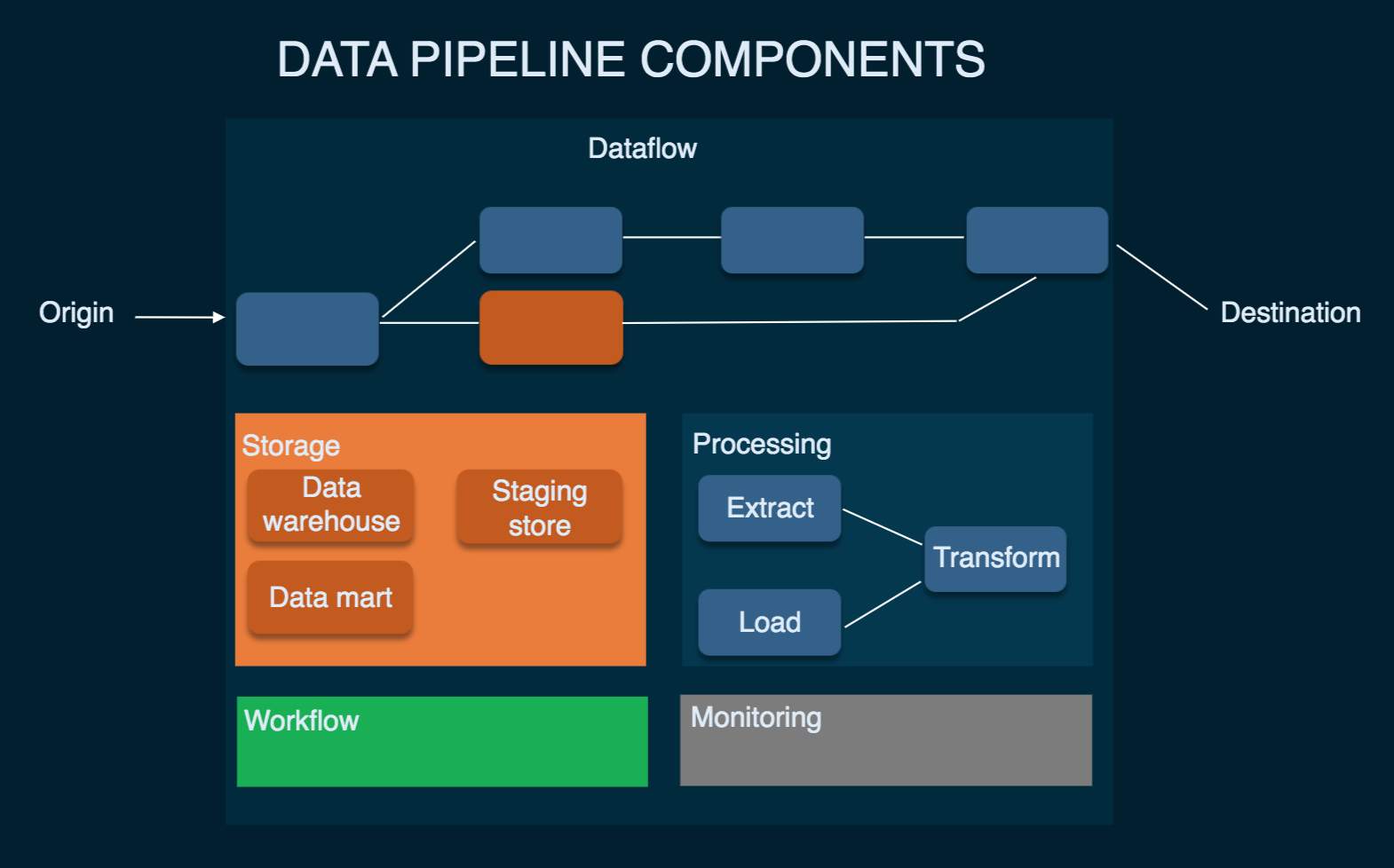
Data pipelines consist of three key elements: a source, a processing step or steps, and a destination. In some data pipelines, the destination may be called a sink. Data pipelines enable the flow of data from an application to a data warehouse, from a data lake to an analytics database, or into a payment processing system, for example. Data pipelines also may have the same source and sink, such that the pipeline is purely about modifying the data set. Any time data is processed between point A and point B (or points B, C, and D), there is a data pipeline between those points.
Data need to be streamlined for Data Science, Machine learning, Business Analytics and Reporting.
The main responsibility of a data scientist is to analyze data and produce suggestions for actions to take to improve a business metric, and then monitor the results of implementing those actions.
In contrast, a data engineer is responsible for implementing the data pipeline to gather and transform data for data scientists to analyze. While data engineer needs to understand the business value of the data being collected and analyzed, their daily tasks will be more oriented around implementing the gathering, filtering, and transformation of data.
Data Pipelines and ETL Pipelines, both signify processes for moving data from one system to the other; they are not entirely the same thing. Below are three key differences:
Data Pipeline Is an Umbrella Term of Which ETL Pipelines Are a Subset. An ETL Pipeline ends with loading the data into a database or data warehouse. A Data Pipeline doesn't always end with the loading. In a Data Pipeline, the loading can instead activate new processes and flows by triggering webhooks in other systems.
ETL Pipelines Always Involve Transformation. ETL is a series of processes extracting data from a source, transforming it, and then loading it into the output destination. Data Pipelines also involve moving data between different systems but do not necessarily include transforming it.
ETL Pipelines Run In Batches While Data Pipelines Run In Real-Time. ETL Pipelines usually run in batches, where data is moved in chunks on a regular schedule. It could be that the pipeline runs twice per day, or at a set time when general system traffic is low. Data Pipelines are often run as a real-time process with streaming computation, meaning that the data is updating continuously.
There are t2 types of data processing systems: online analytical processing (OLAP) and online transaction processing (OLTP). The main difference is that OLAP uses data to gain valuable insights, while the other is purely operational.
Online analytical processing (OLAP) is a system for performing multi-dimensional analysis at high speeds on large volumes of data. Typically, this data is from a data warehouse, data mart, or some other centralized data store. OLAP is ideal for data mining, business intelligence, and complex analytical calculations, as well as business reporting functions like financial analysis, budgeting, and sales forecasting.
Online transactional processing (OLTP) enables the real-time execution of large numbers of database transactions by large numbers of people, typically over the Internet. OLTP systems are behind many of our everyday transactions, from ATMs to in-store purchases to hotel reservations. OLTP can also drive non-financial transactions, including password changes and text messages. OLTP systems use a relational database that process a large number of transactions, enable multi-user access to the same data, rapid processing, provide indexed data sets for rapid searching, retrieval and querying.
A database is any collection of data organized for storage, accessibility, and retrieval. A data warehouse is a type of database the integrates copies of transaction data from disparate source systems and provisions them for analytical use.
Master Data Management helps to create one single master reference source for all critical business data, leading to fewer errors and less redundancy in business processes.
- Snowflake,
- Google BigQuery,
- Amazon Redshift,
- Azure Synapse Analytics,
- and IBM Db2 warehouse.
A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits.
The most common types of data pipelines include:
Batch: When companies need to move a large amount of data regularly, they often choose a batch processing system. With a batch data pipeline, this data is not transferred in real-time but based on a schedule.
Real-Time: In a real-time data pipeline, the data is processed almost instantly. This system is useful when a company needs to process data from a streaming location, such as a connected telemetry or financial market.
Cloud: Data from AWS buckets are optimized to work with cloud-based data. These tools can be hosted in the cloud, and they allow a company to save money on resources and infrastructure. The company relies on the cloud provider's expertise to host the data pipeline and collect the information.
Open-Source: A low-cost alternative to a data pipeline is known as an open-source option. These tools are cheaper than those commercial products, but you need some expertise to use the system. Since the technology is available to the public for free, other users can modify it.
- Talend
- Apache Kafka
- Apache Airflow
The Data Sources can be a variety of systems, such as databases, APIs, and flat files. The data pipelines must extract the data from these sources and bring it into the pipeline.
The Data Transformation component is responsible for transforming the raw data into a usable format. This process may involve cleaning, transforming data types, and aggregating data.
The Data loading component is responsible for loading the transformed data into a target system, such as a data lake or a data warehouse.
The monitoring and alerting component is responsible for monitoring the pipeline for errors and sending alerts if necessary. This component helps ensure that the pipeline runs smoothly and any issues are addressed promptly.
