BigData / Apache Spark
Components of Apache Spark.
Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark's main programming abstraction. RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel.
Spark SQL works with structured data. It allows querying data via SQL as well as the Apache Hive variant of SQLcalled the Hive Query Language (HQL) and it supports many sources of data, including Hive tables, Parquet, and JSON.
Spark Streaming is a Spark component that enables processing of live streams of data. Examples of data streams include log files generated by production web servers or queues of messages containing status updates posted by users of a web service.
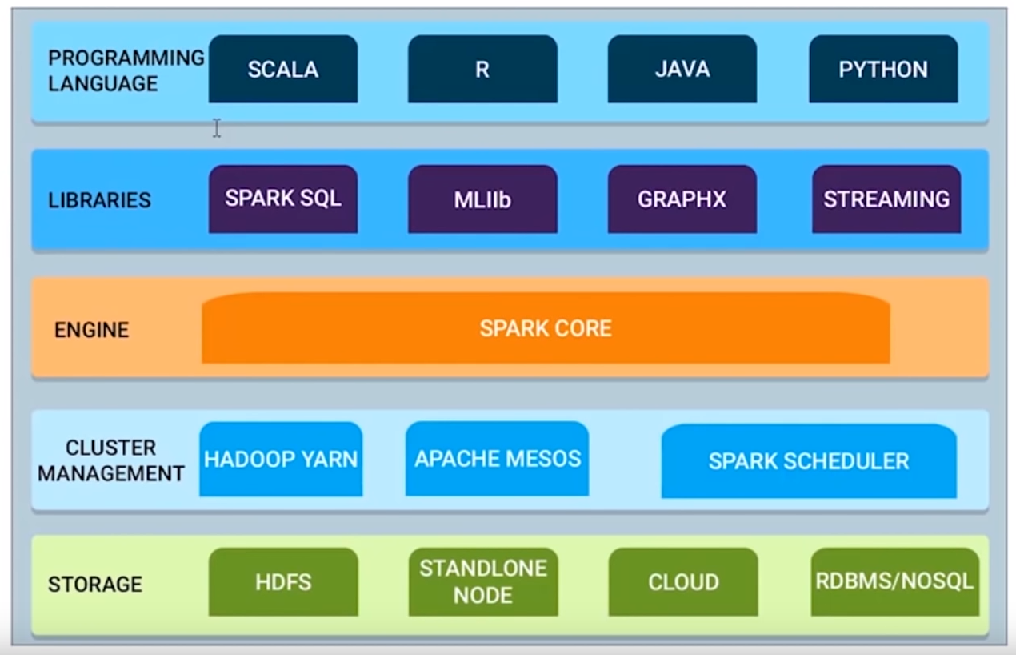
Spark comes with a library containing common machine learning (ML) functionality, called MLlib. MLlib provides various machine learning algorithms, including classification, regression, clustering, and collaborative filtering, as well as supporting functions such as model evaluation and data import. It also provides some lower-level ML primitives, including a generic gradient descent optimization algorithm. All of these methods are designed to scale out across a cluster.
GraphX is a library for manipulating graphs and performing graph-parallel computations.
To achieve this while maximizing flexibility, Spark can run over a variety of cluster managers, including Hadoop YARN, Apache Mesos, and a simple cluster manager included in Spark itself called the Standalone Scheduler.
Invest now in Acorns!!! 🚀
Join Acorns and get your $5 bonus!
Acorns is a micro-investing app that automatically invests your "spare change" from daily purchases into diversified, expert-built portfolios of ETFs. It is designed for beginners, allowing you to start investing with as little as $5. The service automates saving and investing. Disclosure: I may receive a referral bonus.

Invest now!!! Get Free equity stock (US, UK only)!
Use Robinhood app to invest in stocks. It is safe and secure. Use the Referral link to claim your free stock when you sign up!.
The Robinhood app makes it easy to trade stocks, crypto and more.

Webull! Receive free stock by signing up using the link: Webull signup.
More Related questions...
